

안녕하세요 대머리 낙지입니다.
VGGNet을 Pytorch로 직접 모델링하는 과정을 정리해 보겠습니다.
우선 VGGNet이란?
딥러닝을 활용한 이미지 분류 분야에서 초창기에 개발된 모델입니다.
VGG16을 직접 pytorch로 구현해 보겠습니다.
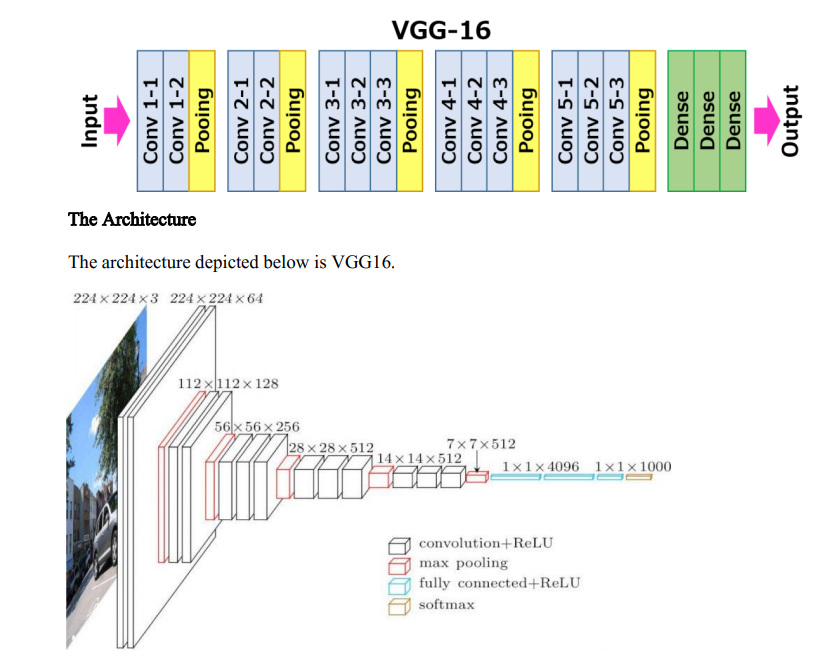
위 그림 위쪽 VGG16의 구조를 보면 conv가 2층이 있는 블록 2개와, conv가 3층이 있는 블록 3개로 featrue extractor가 구성되어 있는 걸 볼 수 있습니다. 각각의 블록을 구현해 보고 조립해서 VGG16을 만들어보겠습니다.
사용할 모듈을 로드해 줍니다.
import torch
import torch.nn as nn
Conv layer가 2층으로 구성된 Conv. Block을 정의합니다.
# VGGNet으ㄹ 위한 conv block 생성 class
class ConvBlock_layer2(nn.Module):
def __init__(self, ch_in, ch_out):
super(ConvBlock_layer2, self).__init__()
self.ch_in = ch_in
self.ch_out = ch_out
self.conv1 = nn.Conv2d(self.ch_in, self.ch_out, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(self.ch_out)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(self.ch_out, self.ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(self.ch_out)
self.relu2 = nn.ReLU()
self.maxpool = nn.MaxPool2d(2)
self.conv_block = nn.Sequential(
self.conv1,
self.bn1,
self.relu1,
self.conv2,
self.bn2,
self.relu2,
self.maxpool,
)
def forward(self, x):
return self.conv_block(x)
conv_block = ConvBlock_layer2(3, 64)
x = torch.randn([8, 3, 32, 32])
out = conv_block(x)
print('test conv block2: ')
print(x.shape)
print(out.shape)
Conv layer가 3층으로 구성된 Conv. Block을 정의합니다.
# VGGNet으ㄹ 위한 conv block 생성 class
class ConvBlock_layer3(nn.Module):
def __init__(self, ch_in, ch_out):
super(ConvBlock_layer3, self).__init__()
self.ch_in = ch_in
self.ch_out = ch_out
self.conv1 = nn.Conv2d(self.ch_in, self.ch_out, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(self.ch_out)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(self.ch_out, self.ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(self.ch_out)
self.relu2 = nn.ReLU()
self.conv3 = nn.Conv2d(self.ch_out, self.ch_out, kernel_size=3, stride=1, padding=1)
self.bn3 = nn.BatchNorm2d(self.ch_out)
self.relu3 = nn.ReLU()
self.maxpool = nn.MaxPool2d(2)
self.conv_block = nn.Sequential(
self.conv1,
self.bn1,
self.relu1,
self.conv2,
self.bn2,
self.relu2,
self.conv3,
self.bn3,
self.relu3,
self.maxpool,
)
def forward(self, x):
return self.conv_block(x)
conv_block = ConvBlock_layer3(3, 64)
x = torch.randn([8, 3, 32, 32])
out = conv_block(x)
print('test conv block3: ')
print(x.shape)
print(out.shape)
마지막으로 VGG16을 정의합니다.
여기서 이미지 크기에 상관없이 동작할 수 있도록 AvgPool2d를 사용해서 feature의 spatial size를 1로 만들어줍니다.
--> 나름 괜찮은 trick 같습니다.
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.conv_block1 = ConvBlock_layer2(3, 64)
self.conv_block2 = ConvBlock_layer2(64, 128)
self.conv_block3 = ConvBlock_layer2(128, 256)
self.conv_block4 = ConvBlock_layer2(256, 512)
self.conv_block5 = ConvBlock_layer2(512, 512)
# feature extraction 결과가 bs X feature X 1 X 1 이 아닐 경우를 위해 추가
self.avgpool = nn.AvgPool2d(1)
self.fc1 = nn.Linear(512, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.out = nn.Linear(4096, 1000)
def forward(self, x):
x = self.conv_block1(x)
x = self.conv_block2(x)
x = self.conv_block3(x)
x = self.conv_block4(x)
x = self.conv_block5(x)
x = self.avgpool(x).squeeze()
x = self.fc1(x)
x = self.fc2(x)
out = self.out(x)
return out
x = torch.randn([8, 3, 32, 32])
model = VGG16()
out = model(x)
print('VGG16:')
print(x.shape)
print(out.shape)각각의 블록 생성 코드 밑에는 잘 구성이 되었는지 확인해 볼 수 있는 print 코드를 넣었습니다.
각 layer 사이에 batch normalization이나 activation function(relu)을 적절히 섞어주시면 좀 더 좋은 성능을 기대할 수 있습니다.
torchvision에서는 유명한 모델들의 구조와 사전학습 weights를 지원합니다.
아래와 같이 모델 출력단의 size만 변경해서 pre-train weights를 활용하면 좀 더 빠르고 정확한 학습을 할 수 있습니다.
import torchvision
model = torchvision.models.vgg19(weights=True)
print(model.classifier)
n_label = 3 # class의 갯수가 3개인 경우
model.classifier[-1] = nn.Linear(4096, n_label)
생성한 모델을 학습시키는 것은 이전의 글을 참고 부탁드립니다.
감사합니다.
[취미생활/Python] - [딥러닝 / Pytorch / 이미지 분석] Classification 예제 정리
[딥러닝 / Pytorch / 이미지 분석] Classification 예제 정리
안녕하세요 대머리 낙지입니다. Pytorch를 활용한 이미지 분류(Classification) 문제를 다루는 전반적인 flow를 기록해보려 합니다. Google colab환경에서 CIFAR10 이미지 데이터를 활용해 간단한 CNN을 돌려
nakzi-lab.tistory.com
'취미 낙지 > Python' 카테고리의 다른 글
| [딥러닝 / Pytorch / 이미지 분석] GAN 기초 (0) | 2023.06.27 |
|---|---|
| [딥러닝 / Pytorch / 이미지 분석] Classification 예제 정리3 - ResNet (0) | 2023.06.26 |
| [딥러닝 / Pytorch / 이미지 분석] Classification 예제 정리1 - 기본 사용법 (0) | 2023.06.25 |


